
2023年显然是无可争议的AI大年,如果对ChatGPT、OpenAI、生成式AI、LLM(大语言模型)等概念一头雾水,那你可能就OUT了。甚至自1956年达特茅斯会议上人工智能(AI)这一概念诞生以来,AI从未距离大众如此之近。所以自然而然的,围绕AI的一切也引发了大量的关注,特别是对于站在浪潮之巅的巨头们关于AI的只言片语,也总能引发诸多的热议。
被称为“AI教父”的杰弗里·辛顿继不久前从谷歌离职后,随即就加入了“AI批评者”的行列,并大谈AI未来可能会带来的风险,甚至还表示,“我对毕生所研究的东西感到后悔”。
就在他态度180°大转弯激起、由“不明真相吃瓜*众”对AI危险性的讨论尚未落幕之时,一个据称是谷歌高级软件工程师Luke Sernau所写的内部信又激起波澜。而这份被泄露的文件中其实只有一个核心主旨,那就是谷歌、OpenAI都没有护城河,开源AI将会摘取这个赛道后的胜利果实。
在这一场生成式AI的“大战”中,谷歌显然只是不折不扣的追赶者。虽然作为阿尔法狗的创造者,多年来谷歌一直扮演着“AI布道者”的角色,但在生成式AI领域,ChatGPT无疑才是领路人。紧随其后的Gооgle Bard公开演示翻车、导致谷歌市值一度蒸发千亿美元后,好不容易推出将生成式AI整合到工作场景的Workspace后,微软融合了GPT-4的Microsoft 365 Copilot又很快把风头抢走了。
所以在外界看来,如今焦虑一词或许才是谷歌在面对生成式AI、LLM时,为真实的写照。
与此同时,领导谷歌前进的CEO皮查伊持有保守倾向、并且也受到了不少的掣肘,以至于谷歌的AI路线图目前并不清晰。在这样的情况下,公司内部的“有识之士”当然也就会心急如焚。
那么问题就来了,作为在生成式AI赛道落后的谷歌有危机感、内部传出悲观论调再正常不过,但为什么会扯上OpenAI呢,或者说为什么开源AI才是终的胜利者?
鲜花着锦烈火烹油,无疑是当下OpenAI的境况。别看这家公司现在几乎是炙手可热的投资标的,但据相关海外科技媒体在近期曝光的新一轮融资文件显示,OpenAI的估值来到了290亿美元。可要知道的是,目前在A股,仅仅寒武纪和昆仑万维这两家AI概念的市值,就已经接近这个数字。换而言之,一手点燃了生成式AI这把火的OpenAI,其实并没有被投资者给出一个惊人的估值。

在许多业内人士看来,OpenAI目前的问题在于缺乏一个清晰的商业模式,他们现阶段唯二可以确定的收入,是一个月20美元的ChatGPT Plus订阅服务,以及1k tokens/0.002美元的ChatGPT API,但这两者显然还不足以让OpenAI盈利。甚至有观点认为,OpenAI现在像极了世纪之交的QQ,尽管同样都是站在相关领域的前沿,但也同样缺乏一个明朗的商业化前景。但后来QQ等来了QQ秀,目前OpenAI却暂时还看不到解决商业化难题的契机。
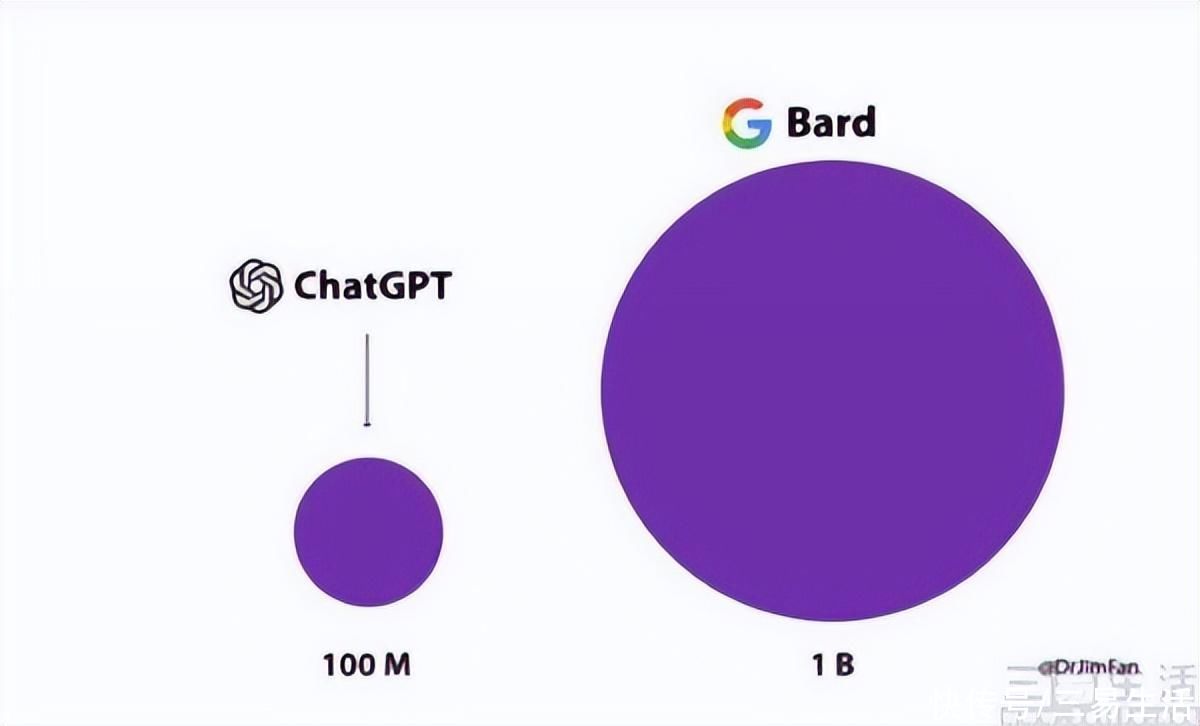
事实上,让谷歌公司的内部人士对谷歌、OpenAI悲观的核心,是生成式AI、或者说LLM本身其实并没有太深的护城河。没错,别看ChatGPT、文心一言这类产品表现得如此智能,但实际上打造一个生成式AI并没有大家想象的那么难。
LLM的理论其实非常简单,即通过分析大量文本数据进行训练,从而学习语言的结构和模式,其所使用的架构也是是长短时记忆网络(Long Short-Term Memory,LSTM)或门控循环单元(Gated Recurrent Unit,GRU)等传统的循环神经网络结构。

LLM更像是“力大砖飞”的结果,然而在ChatGPT一鸣惊人前,业界更青睐的其实是谷歌的Transformer模型。而后者追求的却是如何设计出更小、更快,但更准确的神经网络,甚至于彼时OpenAI的GPT-3是被业界作为负面典型进行评价的。当时就有业内人士表示,“GPT-3在小样本学习中表现出卓越的能力,但它需要使用数千个GPU进行数周的训练,因此很难重新训练或改进。”
ChatGPT的成功就成功在它提出了一个新的思路,毕竟加大参数、加高算力的大模型也是一个方向,并且真的让大模型涌现出了智能。但显而易见的是,这一模式并没有护城河。君不见,即使OpenAI对自己基于人类反馈的强化学习(RLHF)技术秘而不宣,也阻拦不了百度文心一言、*通义千问、谷歌Bard等等一众同类大模型的出现。
此前李彦宏就曾在百度的内部讲话中提到,“算力不能保证我们能够在通用人工智能技术上领先,因为算力是可以买来的,但创新的能力是买不来的,是需要自建的”,也就是说算力和参数都可以买、技术壁垒不高。所以也难怪短时间内国内市场的“百模大战”就已开打,因此先发优势在这里几乎不值一提。
当然,如果没有Meta的LLaMA模型“意外”在4chan上泄露,LLM的技术壁垒不高也只是相对大厂而言。但LLaMA模型的被迫开源,也让开源社区主导了近一段时间针对ChatGPT的“平替”热潮。

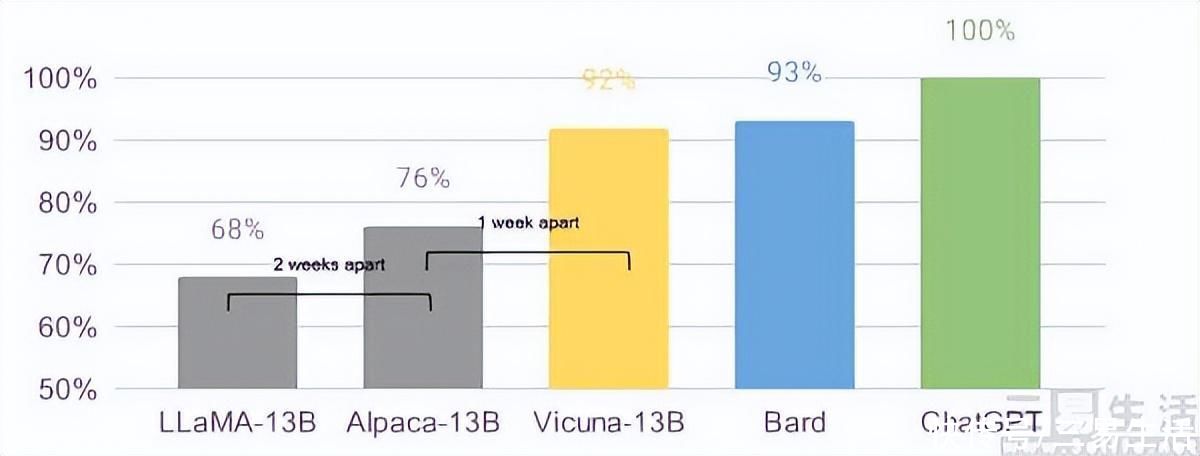
比如说来自斯坦福的Alpaca,借助Llama的预训练模型为基础,仅使用来自GPT模型的一个小尺寸调优数据集(52000个样本),就建立了一个具有对话功能的LLM。而基于LLaMA模型,以及LoRA (Low-Rank Adaptation of LLM,即插件式的微调)训练,开源社区在不到两个月的时间里已接连发布了ChatLLaMa、Alpaca、Vicuna、Koala等模型,并且“羊驼家族”们的实际效果还直追GPT-3.5、甚至不输GPT-4。
借助社区的力量*策*力,并终实现极低成本下的高速迭代,这无疑就是开源AI的优势。就像谷歌这位员工所说的那样,“如果存在一个没有使用限制的免费高质量替代品,谁还会为带有使用限制的谷歌产品买单呢?”
因此从某种意义上来说,谷歌在Android上的做法可能才是佳范例,也就是让开源社区不自觉地为自己的商业利益服务。
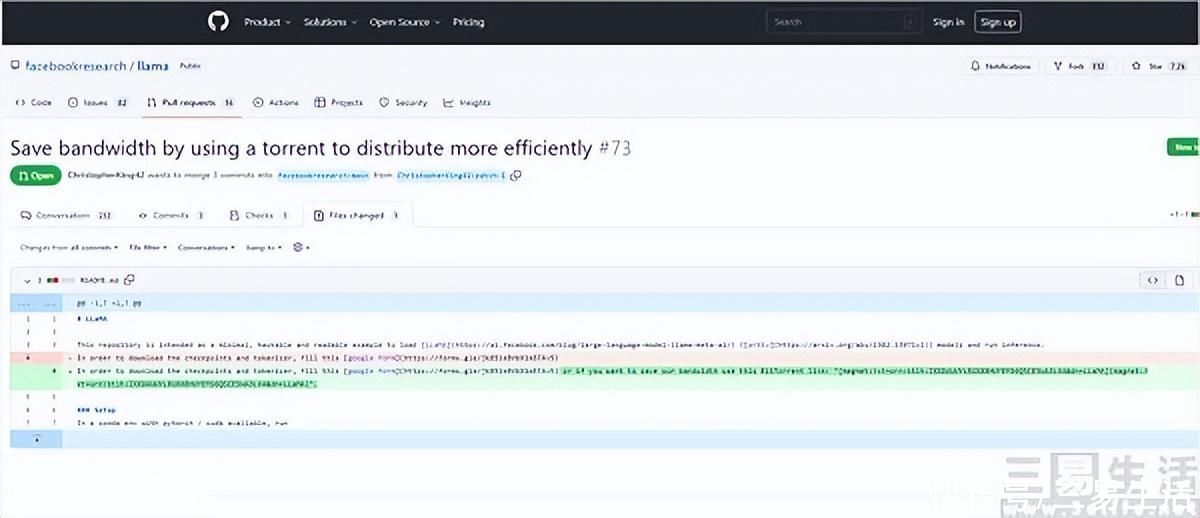
所以不得不说,LLaMA模型泄露更像是一个神来之笔,一下子就让原本掉队的Meta实现了超谷歌、赶OpenAI,毕竟“羊驼家族”就是在Meta的架构之上诞生的产物。
以上就是【百模大战中,笑到后的可能并不是OpenAI】的相关内容,查看其它ai资讯请关注微咔网
根据二〇〇二年一月一日《计算机软件保护条例》第十七条规定:为了学习和研究软件内含的设计思想和原理,通过安装、显示、传输或者存储软件等方式使用软件的,可以不经软件著作权人许可,不向其支付报酬。
本网站所有发布的源码、软件和资料,均为作者提供或网友推荐收集各大资源网站整理而来,仅供功能验证和学习研究使用。
所有资源的文字介绍均为网络转载,本站不保证相关内容真实可信,同时不保证所有资源100%无错可用,也不提供相应的技术支持,介意勿下。
您必须在下载后24小时内删除,不得用于非法商业用途,不得违反国家法律,一切关于该资源的商业行为与本站无关。
如果您喜欢该程序,请支持正版源码,得到更好的正版服务。、如有侵犯你的版合法权益,请邮件与我们联系处理【投诉/建议发送至邮箱:3066548754@qq.com】,本站将立即改正并删除。
本声明为本站所有资源最终声明,所有与本声明不符的表述均以本声明内容为准。
微咔网 » 百模大战中,笑到后的可能并不是OpenAI









